git - 1337 edition - I
I started working at Crio about 7 months ago as a Software Engineer Intern and I had zero industry experience with programming. I was confident in my skills but unsure of their effectiveness in a collaboration environment. What if I mess up, what if someone blames me up for something, I had a gazillion thoughts on my mind. And sharpening up my git skills was paramount.
Well, I don't like hovering over a technology just to get things done, especially when I'm in college and I have the time. I decided to get into it and get into it deep.
Before getting into the specifics, I'd like to drill in why it's important that we use the command line and not GUIs, at least don't start with a GUI. If you start out using Git with one of the graphical tools where they let you drag and drop commits and do all sorts of wizardry, you'll never fully understand what's going on under the hood. And you'll just be left in the dust when it comes to fixing mistakes.
To truly get Git, you have to use the tools as they were designed. And to do that, you need to use git on the command line.
Alright! What is Git? We all know that it's a distributed version control system(DVCS). But to understand git, we need to learn how does git store information.
How does Git store information?
Git was initially a toolkit for a version control system rather than a full user-friendly VCS, it has several subcommands that do low-level work. These commands are generally referred to as Git’s “plumbing” commands, while the more user-friendly commands are called “porcelain” commands. Get it?
At it's core git is like a hash-table1, where the Value is the Data and the Key is the Hash of the Data. 2
The Key - SHA1
- It's a cryptographic hash function.
- Given a piece of data, it produces a 40-digit hexadecimal number.
- If the given input is the same, the value is always the same.
- Because of this feature, remember identical content is always stored once.
So you look at git log, you see lots of 40 digit hexadecimal, those are called SHA1s.
This type of system is also called a Content Addressable Storage (CAS) System.
The Value - BLOB
The most basic git object is called a blob (Binary Large OBject). Git stores the compressed data in a blob, along with the following metadata (data about data) in the header:
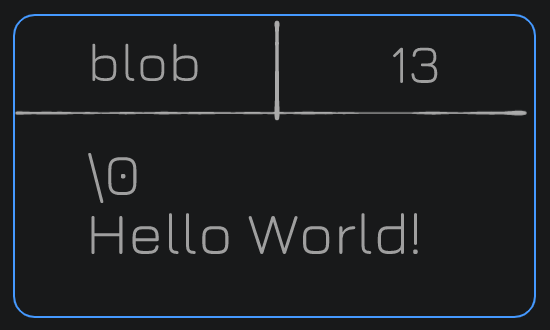
- the identifier blob (saying hey this is a blob)
- the size of the content
- \0 delimiter - It's the null string terminator in C.
- content
Let's ask git for hash of the content: 'Hello World!'
> echo 'Hello World!' | git hash-object --stdin
980a0d5f19a64b4b30a87d4206aade58726b60e3Instead of stdin I can provide a file as well.
How about generating SHA1 of the contents, with metadata with some tools available to generate SHA1 hash.
> echo 'blob 13\0Hello World!' | openssl sha1
(stdin)= 980a0d5f19a64b4b30a87d4206aade58726b60e3Notice it's a match. So, if you'll run the hash function on the same content twice you'll always get the same result and that's one core fundamental features of git. Because of this, blobs are generally unique in git and the likelihood of a collision is infinitesimal.
Blobs are stored in a directory inside ./git/objects directory. That directory's name starts with the first two char of the hash and then the file inside is the rest of the characters. Git does this to do extra optimization. SHA1 are hexadecimal(base 16) so in a complete/full repo objects directory can have at most 256 subdirectories with two char prefixes of SHA1s.
Alright so now we know how git stores content. Are we missing something?
We need something else
The blob is missing some information:
- filenames
- directory structure
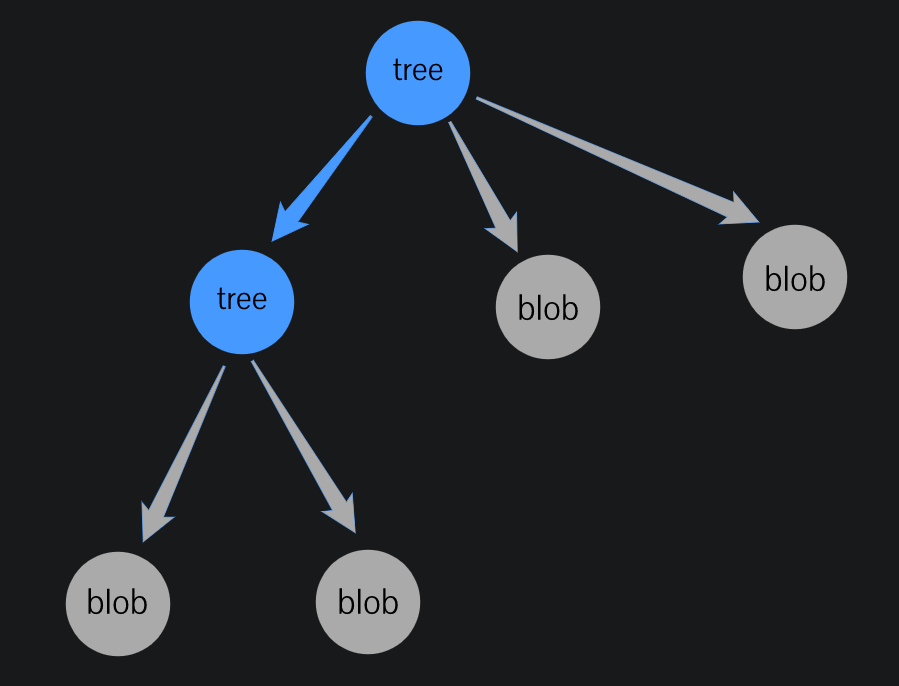
We did store the content in a blob but we don't know where that file was and what was the file's name. Git stores this information in a tree. The tree contains:
- pointers using SHA1 -> to blobs and other trees, and why is that? It's because subdirectories can be nested.
- It also has some metadata (of course)
- type of the pointer (tree or blob)
- filename or directory name of the thing that it's pointing to
- and it stores the mode (is the file executable, or has symbolic links .. etc)
The Tree

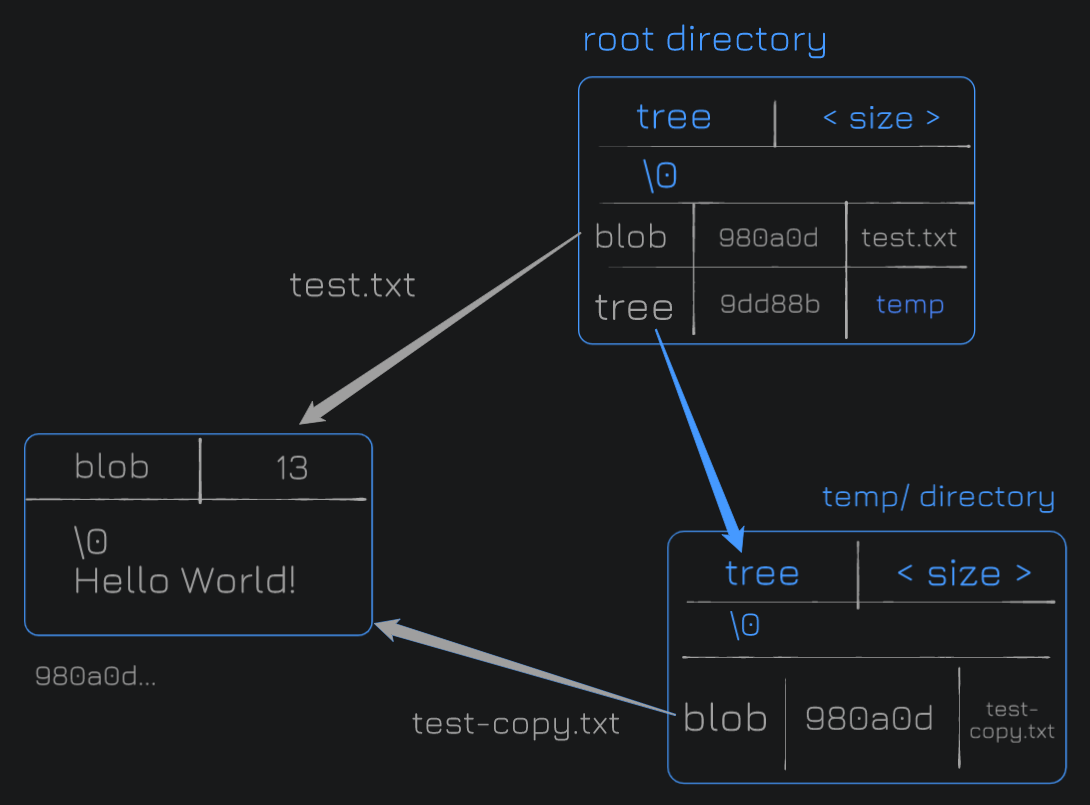
.
├── temp
│ └── test-copy.txt
└── test.txtIn the previous example, I had calculated the size, it was just the number of characters. Here, I have a placeholder. We have that \0 terminator and we have a simple directory structure, we have test.txt, a folder called temp and in that we have a test-copy.txt file. So the blob points to test.txt and the tree points to the temp directory.
Have you ever tried to add an empty directory to git?
Yeah! so git doesn't store empty directories. The issue is not with empty trees, those just work fine, it's a limitation in the staging area. It only keeps track of files and not directories. By the way have you seen people keep .gitkeep files inside directories on GitHub, well they use it to make git keep track of those directories.
Identical content is only stored once
We talked about this in the key (SHA1) section, that same content generated the same SHA1s and git utilizes this fact very well. Let's have a look at the example from above.
Directory Structure:
.
├── temp
│ └── test-copy.txt
└── test.txt
1 directory, 2 filesThe first blob points to test.txt. And we have another tree that points to temp (tree), and in temp, we have another file test-copy.txt (whose contents are the same as of test.txt), which is a blob with the same SHA1, as the content is same.
And this is one of the most critical ideas about git. This is how git saves a ton of space, on your hard drive when storing full repositories. And this is why switching branches is so fast as well.
More Optimizations
We know that as files change, their contents remain mostly similar. You might add a method, a line, or change existing lines/comments. Git optimizes for this by compressing these files together, into a Packfile. The Packfile stores the object, and deltas: the differences between one version of the file and the next.
Packfiles are generated when you have too many objects, during garbage collection (git runs it every few weeks or when you ask it to) or during a push to a remote. If I deep dive into the internals of packfiles, I might have to extend this blog to another month maybe.
But now you have an idea of the compressing deltas message when you push to remote.
Git Commits
Commit Object: A commit points to a tree and contains metadata:
- author and committer
- date
- message
- parent commit (one or more): we might have more parent commits, in case of a merge.
The SHA1 of this commit is the hash of all this information. So a commit looks something like this:

These commits points to trees. And that tree points to other trees and blobs and so on.

Assuming a41cab is the first commit in the repository, this commit won't have a parent. The second commit, i.e. the green circle above it, is pointing to the first commit as its parent. So a tree is essentially a snapshot of the repository which points at files and directories.
Commits under the hood
We know each commit is associated with a SHA1, you can have look at your git log for the same. If you have a look at .git/objects directory and try to cat one of your commits, it'll be a whole lot nothing because it's compressed binary object. So if you wanted to look at them, we can use one of git's plumbing commands git cat-file. It has two useful flags.
❯ git cat-file -t 7b01c # -t flag prints the type
commit
❯ git cat-file -p 7b01c # -p flag prints the contents
tree 441b084f81a05f4a29493bf984ba801e7f7d93ca
parent d4a589d93e27a49ecdb10a62ff3ffbb8981810a8
author Karn <karn.gyan@criodo.com> 1588134949 +0530
committer Karn <karn.gyan@criodo.com> 1588134949 +0530
temp dirSo we know the commit hash is comprised of all these data and even if one of them is changed sha1 changes. And hence we can't change commits. Even if the files don't change, the created date will. You can't change any of the other data in git without changing the IDs of everything after it. And that's a great security feature, which assures you that if you have a commit id, your project is the same as when it was committed and nothing in its history has changed.
Another great thing is it prevents corruption, i.e. if something has gone wrong with your disk, it'll tell you SHAs don't match.
References
Let's go over this quickly(as there's more down under), they're just pointers to commits.
- Tags
- Branches
- HEAD - pointer to the current commit, it's a special reference.
- When you checkout a branch, head also points to the current branch.
Why is changing branches lightning fast in Git?
Under the hood
❯ tree .git
.git
├── HEAD
└── refs
├── heads
│ ├── feature-dark-mode
│ └── master
├── remotes
│ └── origin
│ ├── feature-dark-mode
│ ├── HEAD
│ └── master
└── tags
...If we look at references under the hood, in my .git directory, there are two important places where these references are stored
- HEAD
- refs/heads - Here all your branches lie
❯ git log --oneline
a45c454 (HEAD -> master) update bio
...
❯ cat .git/refs/heads/master
a45c4545fa13f574cfbc9f650ebb3939580aab3eYou can also notice if cat .git/refs/heads/master we get SHA of the latest commit on master. This kind of makes git human-readable ;)
❯ cat .git/HEAD
ref: refs/heads/masterNow if you cat .git/HEAD, you'll see that at this point, HEAD our current branch pointer is also pointing to master and master is pointing to latest commit and hence by transitivity (of some sorts) HEAD is also pointing to the latest commit. There are cases when HEAD points to a commit directly instead of a branch, we'll talk about that later.
You'll also notice that I'm writing this blog directly on my master(not recommended). I guess I will move to dev and set up a dev subdomain soon.
Alright! This will be a long blog so I guess let's cover up what do we know and what have we learned. We talked about three types of objects
- the blob
- the tree
- the commit
We talked about where references are stored and how to see what HEAD points to.
# Git Areas and Stashing Let's talk about the three areas in Git where your code lives:- Working Area:
- Sometimes also called the working tree.
- Files that ain't in your staging area and are also not handled by git, it's just in your local storage. These are called untracked files.
- This is like your scratch space, you can create, modify, and delete content and if the deleted/modified content was in your repository, you don't have to worry about it.
- Staging Area:
- You might also see people call it the cache or the index.
- These represent what files are going to be part of the next commit.
- Repository:
- Files that git knows about and it contains all your commits.
Closer Look: Staging Area
By this area, git knows what will change between the current commit and the next commit.
Tip: a clean staging area isn't empty.
Staging area consists of the exact copy of your latest commit. And when you change anything, git knows you changed because the SHA1s in the exact copy don't match. You can use the following plumbing command to see what's in your staging area.
❯ git ls-files -s
100644 455d1e9fddf196ddf1b7109c280bfee188a73b1a 0 .editorconfig
100644 d0b459c6c00d0882d4b3b584cbd29572783ddca9 0 .gitignore
100644 9ae00f2d15642a957660ade764e81250260bf414 0 404.html
100644 9407e3bf8303dd14b195ebb40afb45355728b9ab 0 CNAME
100644 a23468905b969c706858dcd294d6421d010c00bf 0 FAQ.md
...I hope you all are familiar with moving files in and out of the staging area. (git add, git rm, git mv)
- git add - Add file to next commit
- git rm - Remove file from next commit
- git mv - Rename file in next commit
git add -p
I use it a lot in my workplace, and it's my absolute favorite. It's especially useful if you've done too much work for one commit. It allows you to stage commits in hunks interactively.
Tip: Remember to use ? for help.
Git Stash
There's one more place where git stores code. The stash is safe from destructive operations and this is where we save un-committed work. It's handy for a bunch of works, for example switching branches when you're in the middle of work if you're using commands like git reset that may change or overwrite existing work.
Basic Use:
git stash # stash changes
git stash --include-untracked # stash untracked files as well, they'll still be untracked
git stash --all # even ignored ones (.gitignore ;))
git stash list # list stash :P
git stash show stash@{0} # show contents of stash@{0}
git stash apply # apply the last stash
git stash apply stash@{0} # apply a specific stash
git stash drop # delete the last stashAdvanced Stashing Operations:
git stash save "WIP: making progress on git blog" # name stashes for easy ref
git stash branch <optional branch name> # start a new branch from stash
git checkout <stash name> -- <filename> # grab a single file from stash
git stash pop # remove the last stash and apply
git stash drop stash@{n} # remove nth stash
git stash clear # remove all stashesI use stash --include-untracked, stash save "WIP..", stash pop, stash clear a lot.
Although if you're interested you can also use git stash -p, similar to git add -p which allows you to selectively stash changes.
Git References
What's a branch?
A branch is just a pointer to a particular commit. The pointer of the current branch changes as new commits is made.

You can learn more about git branching with really cool visualization from Learn Git Branching3.
I tend to refrain from external links in my blogs, as it deviates the reader's attention, so I recommend checking this out after you're done with the blog.
What's a HEAD?
Head is how git knows what branch you're currently on, and what the next parent will be. It's a pointer that usually points at the name of the current branch. But, it can point at a commit too (detached HEAD).

HEAD moves when you make a commit in the currently active branch and when you checkout a new branch.
Tags & Annotated Tags
Lightweight Tags
These are just a simple pointer to a commit. When you create a tag with no arguments, it captures the value in HEAD.
❯ git tag my-first-tag
Annotated Tags: git tag -a
They also point to commits but store additional information.
- author
- message
- date
You can pass in -m just like a commit, to add a message.
❯ git tag -a v1.0 -m "Version 1.0 of my blog"
❯ git tag # list all tags we have two here: lightweight and annotated
my-first-tag
v1.0
❯ git show v1.0
tag v1.0
Tagger: Karn <karn.gyan@criodo.com>
Date: Thu Apr 30 09:42:21 2020 +0530
Version 1.0 of my blogYou can look at all the information using git show < tag name > about the tag. In practice, lightweight tags are not used that much. Annotated tags are much more useful. Here's a bunch of commands that'' come in handy when you're meddling with tags the next time:
git show-ref --tags # list all tags with what commit they're pointing at
git tag --points-at <commit> # list all tags pointing at commit
git show <tag-name> # look at the tagNote: The current branch pointer moves with every commit to the repo. But the commit that a tag point to doesn't change.
Head-Less / Detached Head
This is probably a scary message and many of us have been here. I feel it's like a rite of passage in the learning of git. Let's see how this state arises: Sometimes you want to checkout a specific commit (or tag) instead of a branch, git will simply move the HEAD pointer to that commit and it'll point to the next SHA. This state is a detached state. Now suppose, you have checked out a commit (via a git checkout < commit-id >):
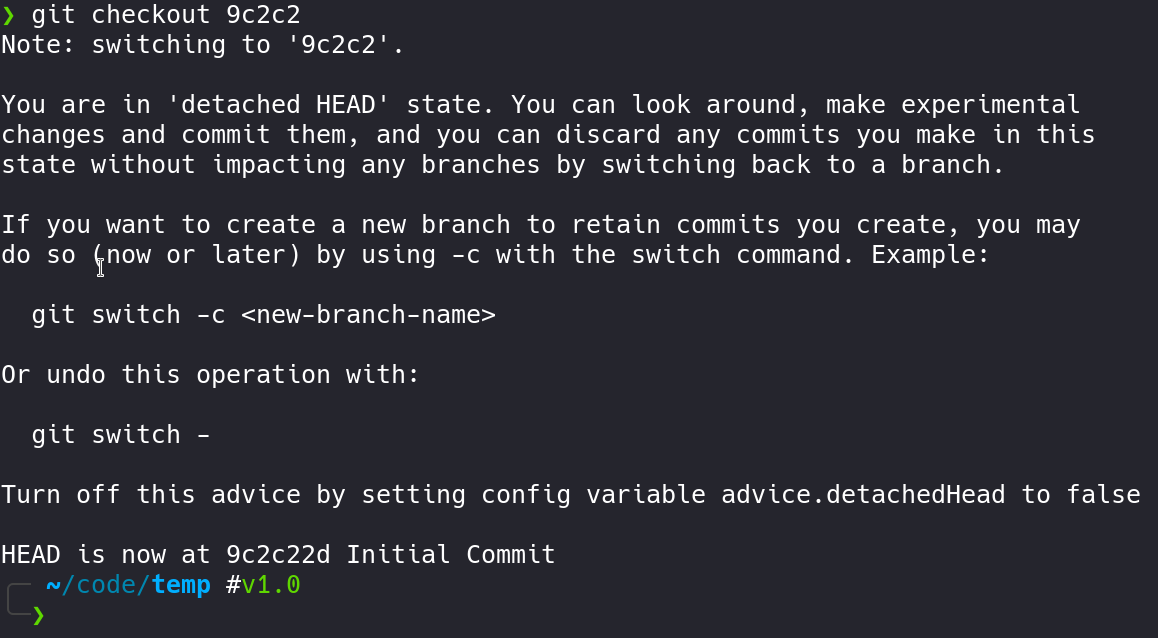
Git tells you that you're in a detached HEAD state and any commits you make here and do not do something about it (i.e. create a new branch out of it) consider them lost. There are ways of getting them back and we'll talk about git disaster recovery soon, but if you don't do anything with them, poof.
There are a few things we can do to save our work in a detached state.
- Create a new branch that points to the last commit you made in a detached state.
- git branch < new-branch-name > < commit >
- Why last commit?
- Because other commits point to their parents.
- So if you just point it to the last commit, history is preserved automatically.
Okay, let's make a commit. Hehe!
These commits are actually called dangling commits.
If you care about them, create branch out of it, else forget about it, check out any of your existing branches and continue your work. Eventually, the garbage collector will clean 'em up. Yeah, git has garbage collection. I think I talked about it somewhere above.
Merging
Merge Commits
Under the hood, merge commits are just commits, but they happen to have more that one parent (i.e coming from different branches). Most merge commits probably have two parents, but entirely possible two have any number of parents getting merged into one commit.
You can think of merge commits as a marker as to when a feature branch got merged to master.
If you have ever merged two branches, you must have come across a term called fast-forward. Fast-forwarding happens when there is a clear path between the tip of the current branch to the tip of the target branch. For example: Hereafter we branched out feature, there were no more commits to master.
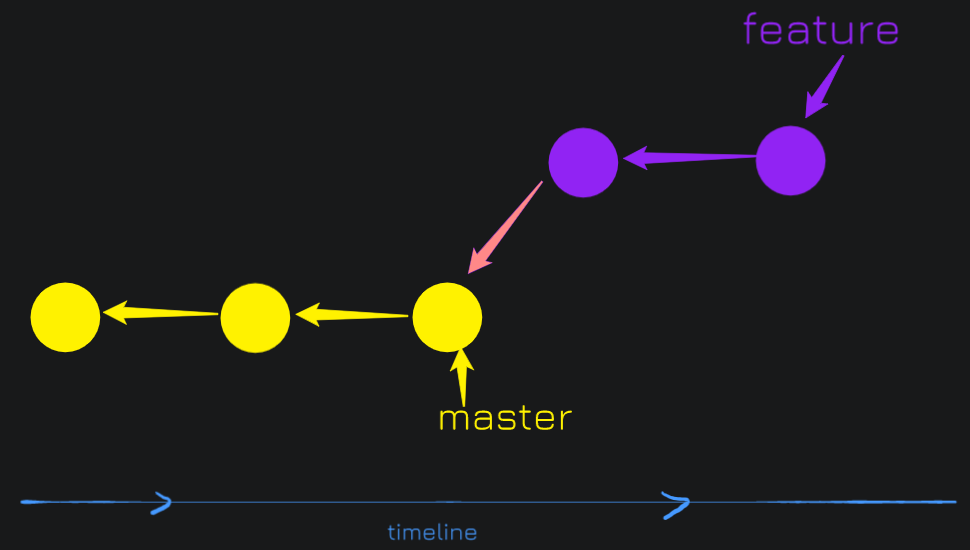
During a fast forward commit, we add the new commits on top of the master branch and we just move the master pointer. In this case, we did not have to make a merge commit. Git knew how to move that pointer automatically.
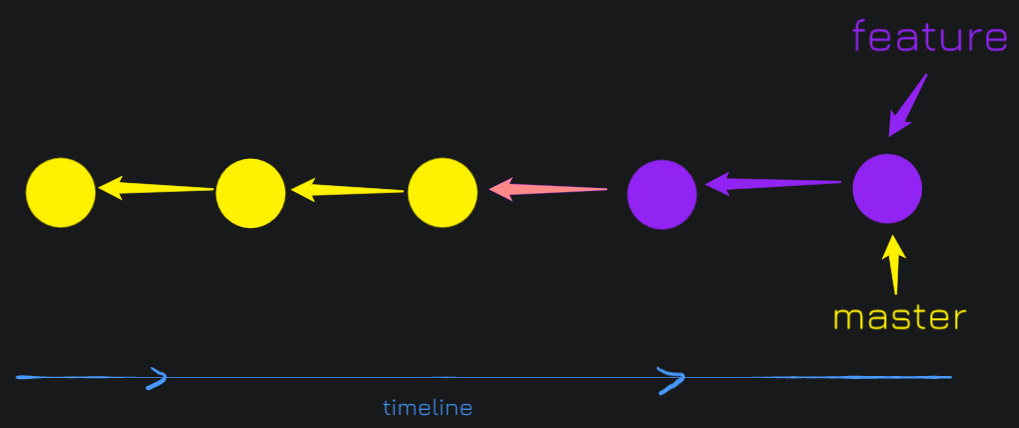
The problem with fast-forward is, we can lose track of a feature that was merged back into master. As when you're working on a feature and you merge it back into master, you'd like a clear delineator of the work that was done in that branch. Otherwise, we might have trouble finding out what feature caused the bug, 'cause these commits are just linear.
So in order to avoid this, use
- git merge --no-ff
- this will force a merge commit even when one isn't necessary.

Merge Conflicts
When you attempt to merge, but your files have diverged. This creates a state called merge conflict. Git creates a new file which will contain those conflicts, you can make edits, have the solution and then commit, and continue. Note that Git stops until all the conflicts are resolved. Later down the blog, we'll cover what happens when your merges go horribly wrong and how to fix that.
As of now, I'd like to introduce you to this really cool tool called Git ReReRe - Reuse Recorded Resolution.
It saves how you resolved a conflict, and next conflict it's gonna use the same resolution. It's really useful for a long-lived feature branch (like a refactor), or when you're rebasing. Have you ever tried rebasing and every time you rebase, merge conflicts keep coming over and over again? Oh Yeah! that's messed up. So this is gonna save you.
Alright! so how do we use it? We gotta turn it on. And enjoy life.
git config rerere.enabled true # use --global flag for all projectsNote that you must still git add and git commit! You should always inspect the merge results (and/or run tests)—though you should do this always, regardless of your rerere.enabled setting.
Here's a quick ReReRe Demo for your pleasure. In the video, I have tried to create a merge conflict and resolve it while git rerere records that. I repeat the same after a hard reset to show you the rerere magic.
History and Diffs
First of all, stop writing Bad Commit Messages, I don't want to debug at midnight and go through the history to see commit messages like "More Code", "Here have code", etc. For a project where you're collaborating with a bunch of people, just don't write bad messages. It compounds over time and coders who join later think that it's okay to write such messages here and they propagate the same.
Why good commits are important?
It helps you preserve the history of a codebase.
They help you with:
- debugging, troubleshooting
- creating release notes
- code reviews
- rolling back
- associating the code with an issue
A good commit message:
- Write it in the future tense, example use fix instead of fixed.
- If the code is not simple and requires a descriptive message:
- Write a short subject, followed by a blank line and lastly a description
- The description should be small, don't mention what you did, try to answer the hows
- Mention side effects, current scenarios
- Break description into 72 character lines for better formatting
- A good commit shouldn't leave your code in a broken state, i.e. tests must pass.
git log
To examine the history, we can use git log that shows the history of your repo. The vanilla git log isn't very helpful. But there's a lot of really cool features and flags that help us navigate our repository a lot easier.
- git log --since
git log --since="yesterday"
git log --since="2 weeks ago"- git log --follow: You can follow a file that has been moved or renamed
git log --name-status --follow -- <file>--name-status also shows you what the name changed to when a modification to the file happened.
- git log --grep < regex >: You can search for commit messages that match a regular expression
- It can also mixed and matched with other git flags.
- Example:
git log --grep=mail --author=karn --since=2.weeks - git log diff-filter: Selectively include or exclude files that have been (A)dded, (D)eleted, (M)odified, (R)enamed & more.
git log --diff-filter=R --statReferencing commits
This confuses people all the time, even I google it sometimes.
- ^ or ^n (hat)
- no args means ^1, i.e. the first parent commit
- n: the nth parent commit
- ~ or ~n (tilde)
- no args means ~1, i.e first commit back, following 1st parent
- n: the number of commits back, following only 1st parent
~ and ^ can be combined.
Let's understand these better with an example.
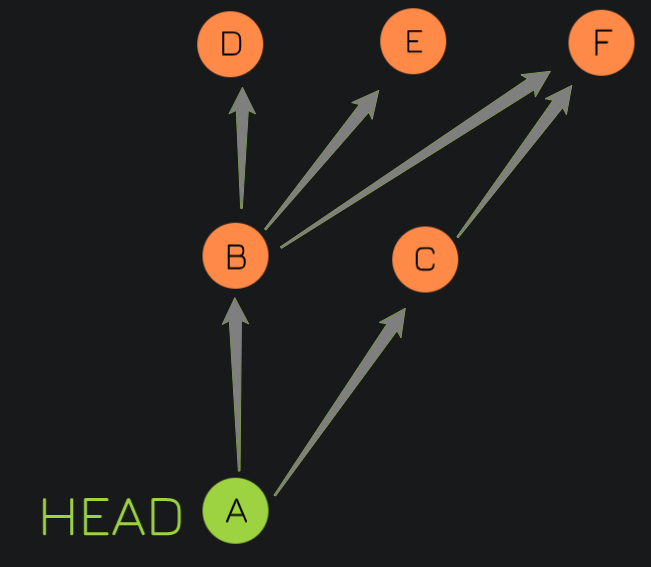
Both commit nodes B and C are parents of commit node A. Parent commits are ordered left to right. And A is the latest commit. (Merge commit of B & C)
- A = A^0
- B = A^ = A^1 = A~1
- C = A^2
- D = A^^ = A^1^1 = A~2
- E = B^2 = A^^2
- F = B^3 = A^^3 = A^2^1
I probably use tilde more frequently that the hat. It's useful when you want to do a revert like 3 commits ago.
git show: Look at a commit
This is pretty basic. Just do a git show on any commit, it'll show up.
git show <commit> # show commit and contents
git show <commit> --stat # show file changed in commit
git show <commit>:<file> # look at a specific file in a commitgit diff
Another common tool, it shows you changes between commits, between the staging area and the repository and what's in the working area.
git diff # unstaged changes
git diff --staged # staged changesExtra note:
- To look at the branches merged into master
git branch --merged master- To look at the branches not merged into master
git branch --no-merged masterThat's about it for the part one, you can continue on to the next part.
Footnotes
- https://karngyan.com/hash-tables-1/ ↩
- Illustrations used have been drawn on Sketch Pad ↩
- https://learngitbranching.js.org ↩